# Harnessing Web Data Extraction and Insights for Competitive Analysis: A Noon Food Exploration
## Navigating the Digital Gastronomy with Python
In today's fast-paced digital marketplace, understanding the competitive landscape and consumer preferences is not just an advantage—it's a necessity. The potential for food service businesses to out maneuver competition and innovate in the culinary space is a testament to the strategic importance of web data extraction. Python, with its rich ecosystem of libraries such as `requests` and `BeautifulSoup`, emerges as a potent tool for this endeavor, simplifying the extraction and analysis of complex web data.
## The Art and Science of Web Scraping
Web scraping transcends mere data collection; it's about strategically navigating and extracting from a myriad of web architectures—from static HTML pages to dynamic, JavaScript-heavy web applications. The distinction between scraping static websites and dynamic web applications lies in their content delivery mechanisms. Static websites serve fully formed pages from the server, while dynamic applications rely on client-side scripts and API calls to render content, presenting unique challenges and opportunities for data extraction.
### Data Extraction Strategies
1. **Static Content Extraction**: For straightforward, HTML-based content, libraries like `BeautifulSoup` offer a seamless way to parse and extract information, ideal for static web pages.
2. **Dynamic Content Engagement**: Dynamic sites, where content is loaded asynchronously via JavaScript, necessitate tools like `Selenium` or `Puppeteer` to automate and interact with web browsers, ensuring all content is rendered and ready for scraping.
3. **API-driven Data Harvesting**: Often, the most efficient path to data lies in intercepting the API calls made by web applications. This approach bypasses the need for rendering pages, directly accessing the data in its raw form.
### Practical Execution: Scraping with Precision
### Step: 1 Understanding the user journey:
Understanding the intended user jouney of the website become crucial as the mechanism of orchestrating the experience typically drives the content delivery strategy to the front-end.
### Step 2: Intercept API Calls:
By examining the network traffic during key interactions, we identify API endpoints responsible for serving personalized content, such as the restaurant listings and menu details based on the selected location.
### Step 3:Scraping Strategy Implementation:
Utilizing Python's `requests.Session`, we emulate the setting of the user's location to 'Al Satwa' in Dubai. Following this, we target the identified API endpoints to extract data on restaurant rankings, menu offerings, and promotional activities—all crucial for competitive analysis.
## A Noon Food Case Study:
Noon Food, a prominent player in the Middle East's e-commerce sector, serves as an exemplary case study. For competitive business in the food service industry, understanding how aggregators position their franchises and the nuances of competitive offerings is crucial. The initial step in scraping Noon Food involves mapping the user journey and identifying key interactions that trigger data loading, such as location selection and menu browsing.
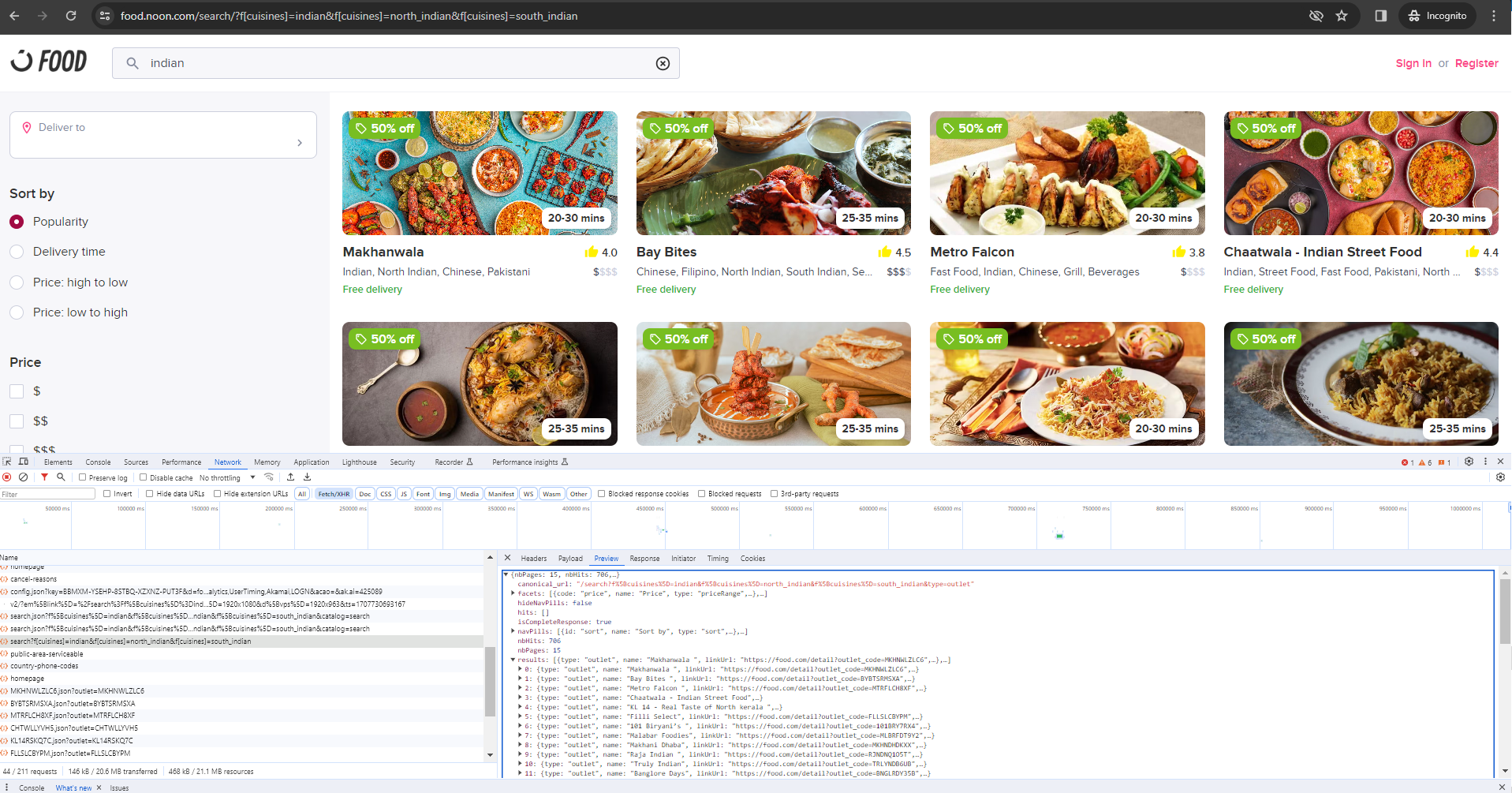
In the case of food.noon.com (refer below image), the landing page requests the users to select a location. This is mostly done geofence the catalog visibility based on the users location preference. Select an area of choice.
Inspecting the network activity of the web page using Ctrl+Shift+I, we can notice that on selecting a particular location, a `POST` request is made to set the cookie associated to the preference of the location
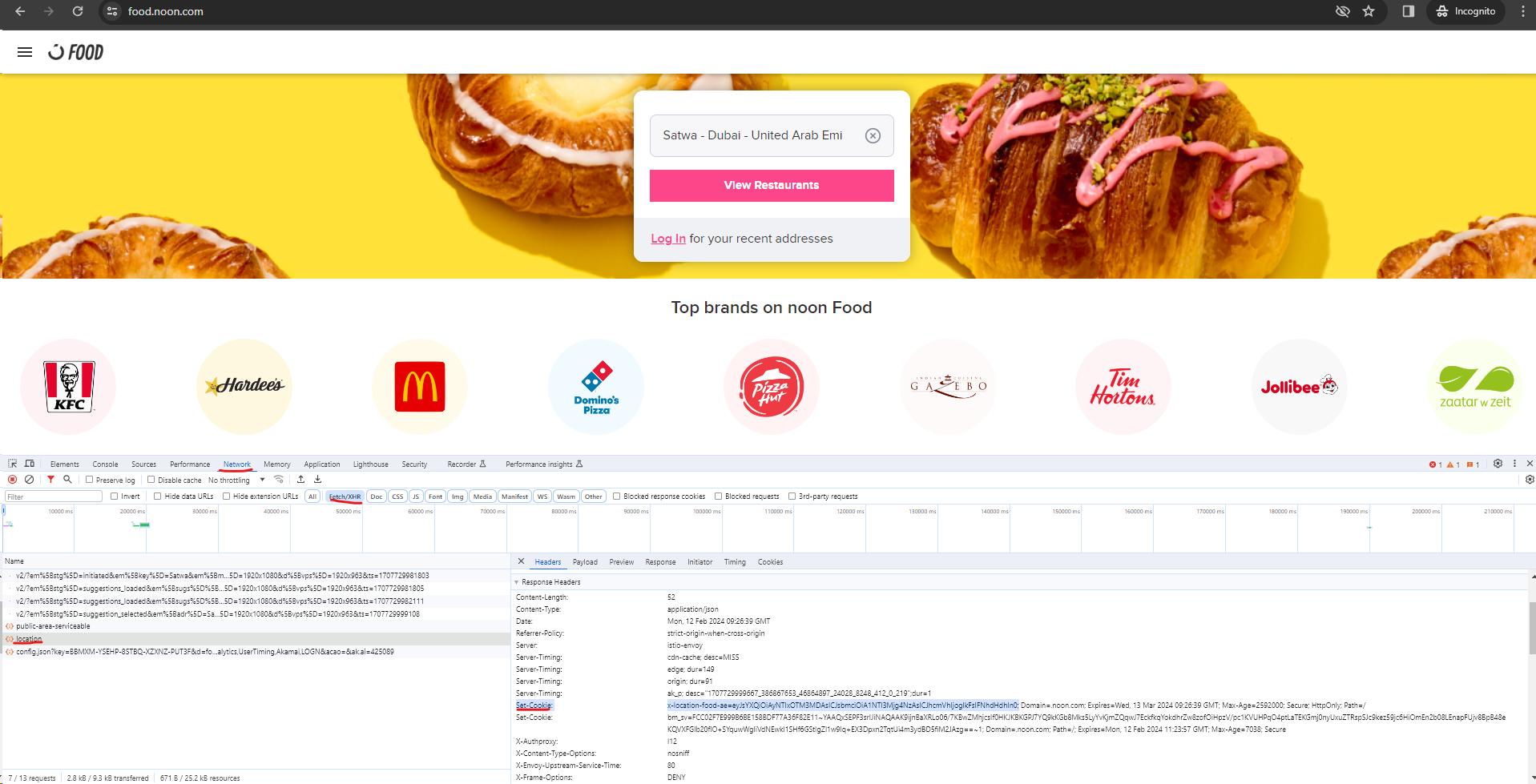
We notice that the following API calls that are made by the client during the interactions.
- `public-area-servicable`: This seems to be an API call that takes lat and long inputs based on the selection as payload and send a response to indicate if the area is servicable.
- `location`: If the area is serviable, this api set the cookie for the location (lat long)
Clicking "View Restaurants" invokes a other APIs necessary to populate the content of the page. Each element on the page can be attributed to an API response. Some websites respond with json objects while others (e.g., amazon) have html content within the json objects.
In the case of noon, What is interesting here the endpoint "api" which seems to populate the home page for a guest user based on the location specified. Scraping this endpoint will reveal all the options a user has access to based on the location selected and the default preference set by noon. This now become crucial competitive information for other competing or complimenting food service brands to be able to plan their demand and operations.
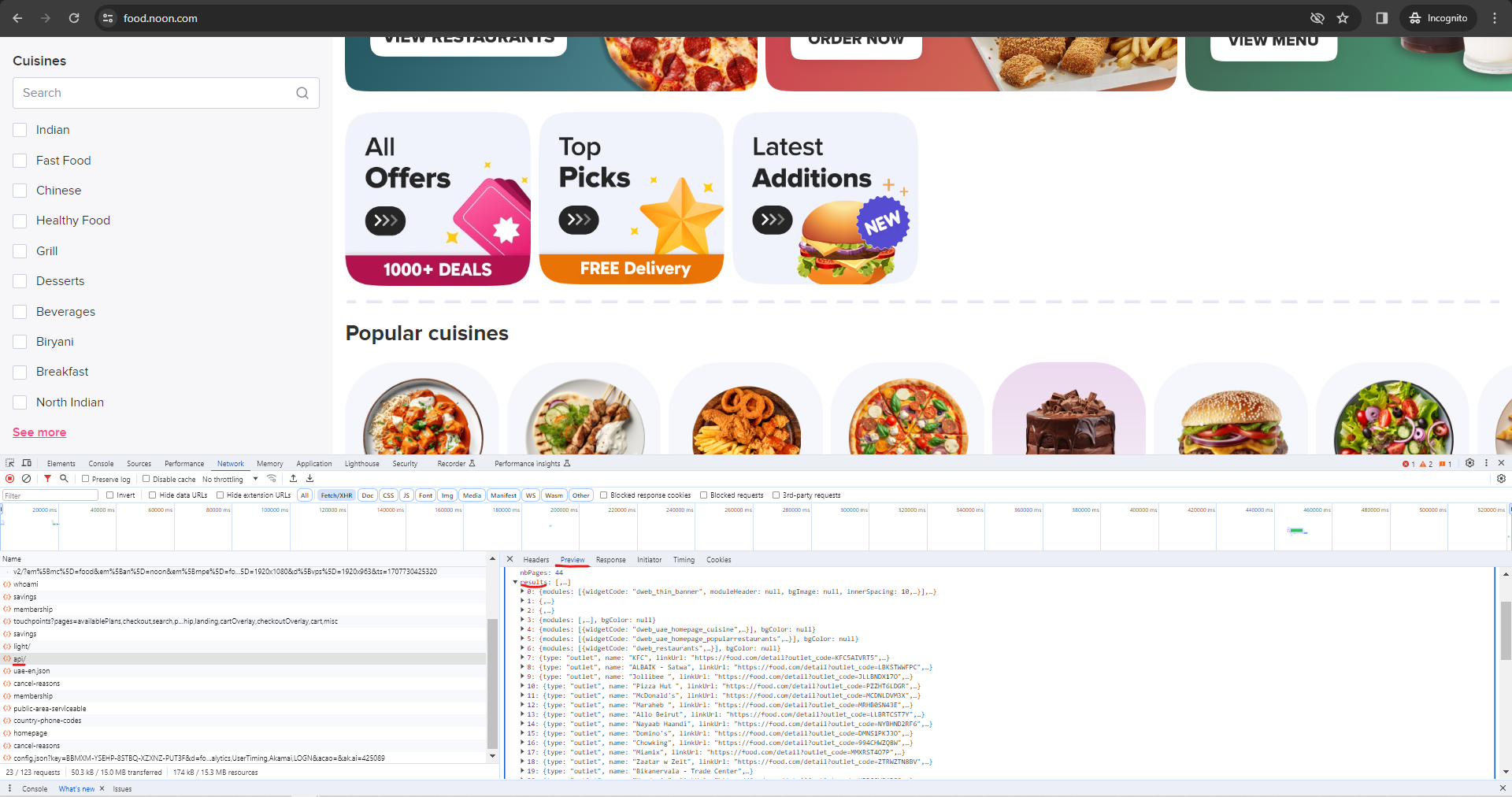
Carefully observing the backend network calls based on interactions with other elements also exposes latent APIs that can be leveraged for a more focused scraping initative. E.g. if the scope of interest is only for "Indian Cuisine".
Endpoints can be further explored to understand a the URL pattern and scale the data extraction as per need.
## Demo
Python and a built in library `requests` is sufficient to be able to implement this strategy and scale it based on need.
```python
import requests
# Initialize a session object
session = requests.Session()
# Set necessary headers for the POST request to set the location
headers = {
"Accept": "application/json, text/plain, */*",
"Content-Type": "application/json",
"Origin": "https://food.noon.com",
"Referer": "https://food.noon.com/",
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36",
"X-Content": "desktop",
"X-Experience": "food",
"X-Locale": "en-ae",
"X-Mp": "noon",
"X-Platform": "web",
# Add any other necessary headers here
}
# The URL to set the location
location_url = "https://food.noon.com/_svc/customer-v1/customer/location"
# Data payload for the POST request to set location, adjust the values accordingly
location_data = {
"lat": 252193700, # Example latitude
"lng": 552728870, # Example longitude
"area": "Al Satwa" # Example area
}
# Make the POST request to set the location
location_response = session.post(location_url, headers=headers, json=location_data)
# Check if the location was set successfully
if location_response.status_code == 200:
print("Location set successfully.")
else:
print(f"Failed to set location, status code: {location_response.status_code}")
```
```
Output:
Location set successfully.
```
Note:
1. Header options can be studied from the network activity tab of the inspect panel. Header contents dependencies varies based on backend, a trail and error approach can be use to understand the minimum header requirments for an API call.
2. The `Session` object from requests handle the cookie information between the calls.
```python
# Set headers to mimic the request accurately
headers = {
"Accept": "application/json, text/plain, */*",
"Accept-Language": "en-AE,en-GB;q=0.9,en-US;q=0.8,en;q=0.7",
"Cache-Control": "no-cache, max-age=0, must-revalidate, no-store",
"Referer": "https://food.noon.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36",
"X-Platform": "web",
"X-Locale": "en-ae",
}
params = {
"page": 2
}
# Now you can make further requests using the same session, and the cookies, including the location, will be automatically included
# Example: Fetching search results using the set location
search_url = "https://food.noon.com/_svc/mp-food-api-catalog/api/"
search_response = session.get(search_url, headers=headers, params=params)
# Check if the search was successful
if search_response.status_code == 200:
search_results = search_response.json()
print("Search results:", search_results)
else:
print(f"Failed to fetch search results, status code: {search_response.status_code}")
```
### Insights and Innovations
By analyzing the extracted data, invaluable insights into brand positioning across aggregators can be obtained and used for a competitive edge, identify trending culinary preferences and even spot gaps in the market for innovative product development. This proactive approach to data-driven decision-making enables food service business to stay ahead in the competitive culinary landscape, ensuring the best quality and delivery times in line with customer expectations.
### Scaling Your Web Scraping Operation
As you plan to extract large amounts of data or perform frequent updates, scalability becomes a crucial factor. Here are strategies to ensure your scraping process can grow:
- Rate Limiting: Implement delays between requests to avoid overwhelming the server, adhering to the site's robots.txt file.
- Concurrent Scraping: Python's asyncio or external libraries like Scrapy can manage multiple requests in parallel, significantly speeding up the data collection process.
- Handling IP Blocks: Utilize proxy servers and rotate IP addresses to prevent being blocked by the website.
- Data Storage: Consider scalable storage solutions, such as cloud databases, to handle the volume of data efficiently.
## Conclusion: The Competitive Edge of Informed Decision-Making
In the realm of food tech and culinary innovation, staying informed about the competitive landscape and consumer trends is not optional—it's imperative. The strategic application of web scraping and big data analysis, as demonstrated through the Noon Food exploration, is a powerful methodology for gaining this insight.