# Retrieval Augmented Generation (RAG) - The fulcrum for AI power applications
## Introduction
### Large Language Models
Large language models have caught the eye of everyone. The term AI has come into the spotlight unlike any other concept now. The buzz around the word `ChatGPT` has skyrocketed since it public reveal and announcement that it has been turn heads all around with its capabilities of being a "know it all" and the potential areas application for this type of technology. In my opinion, this piece of technology has started to democratize information access and curation at a level far superior than when the internet was introduced.
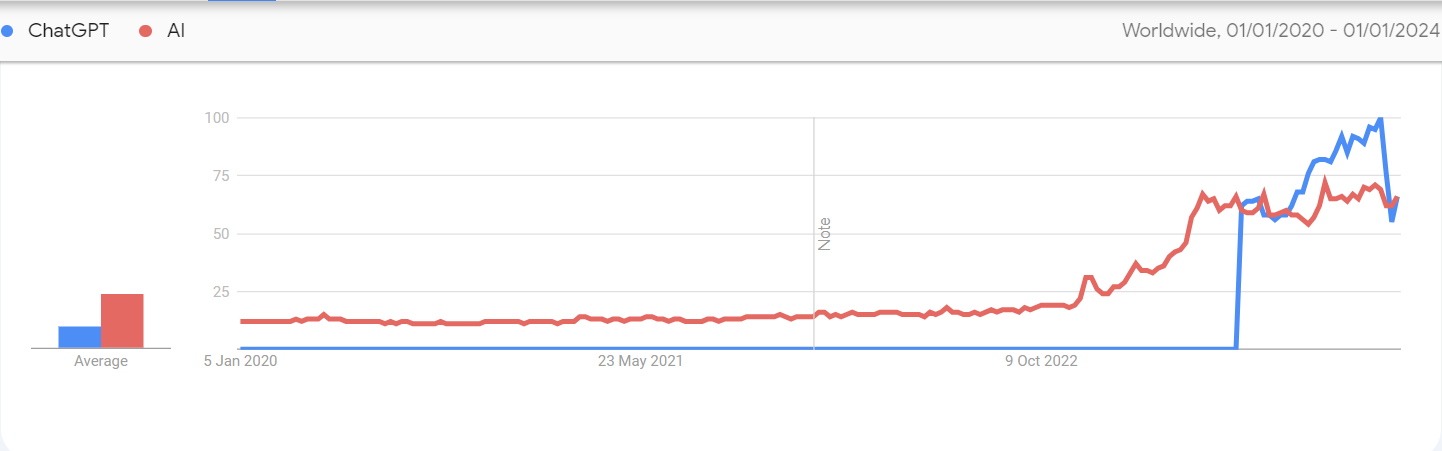
*Google trends Interest over time of ChatGPT and AI over time [image-source: Google Trends](https://trends.google.com/trends/)*
```
“English is the hottest new programming language.”
- Andrei Karparthy
```
LLMs are a subclass of Artificial Intelligence (AI). AI is a broad term, but generally refers to intelligent machines. Machine Learning is the art of finding patterns in the data and applying the patterns to new observations for a predictive edge. Deep Learning is the area of machine learning more specifically for unstructured data like text, images and video and LLMs is a subfield of deep learning that focuses on unstructed text data.
LLMs, specifically those based on the transformer architecture are essentially stochastic word preditors. Fundementally, it is a deep learning model designed to predict the next elements in a sequence of words. While earlier, more rudimentary language models operated sequentially, drawing from a probability distribution of words within training data to predict the next work, LLMs based on transformer architecture are able to consider a larger "context" for thier preditions.
LLMs are trained on vast amounts of text sourced from the internet. While open source models are trained of data that is openly available, closed models like GPT3 and GPT4 have been trained on a curated dataset to carefully optimize the offering. This aspect of the LLMs trained on vast amounts of text is what makes them able to not only carry out instructions (E.g. Summarization), but to also answer common knowledge questions.
## What if the LLM doest know the answer ?
Unfortunately, LLMs by themselves, based on their auto regressive nature, learn to only generate text, not text that is factually true. Nothing in its training gives the model any indicator of the truth or reliability of any of the training data. This aspect of LLMs allow them to hallucinate, which is a phenomenon where they make up facts when they should'nt. There is an active area in research which is focusing on making llms less prone to hallucinations, and only time will tell if the issue can be fully resolved.
### Does that mean that LLMs cannot be fit for real world use cases for query applications ?
Of course not, this limitation can be made up post haste, to an extent. It is achieved by grounding them with aditional context along with the query. There is a growing area of application called RAG (retrival augemented generation) which uses techniques of advanced NLP to be able to ground the LLMs with necessary context enaling them to become query engines on steriods!
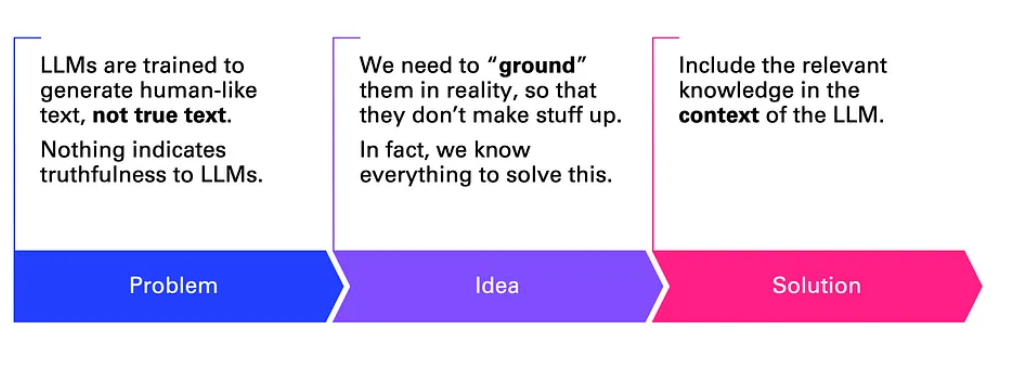
*The process of enhancing LLMs with RAG. [image-source: Medium Article](https://medium.com/data-science-at-microsoft/how-large-language-models-work-91c362f5b78f)*
## RAG
Retrieval Augmented Generation (RAG) is a cutting-edge approach that enhances Large Language Models (LLMs) by integrating them with specific, contextual data. This technology bridges the gap between generic potentially false query output and tailored, context-specific mostly accurate answers. This expands the application and relability of LLMs to any domain. The focus then turns to how relevant context can be provided for LLMs based on the application need and the context requirements.
Below is the example of Bing Chat, one of the first implementations of RAG.
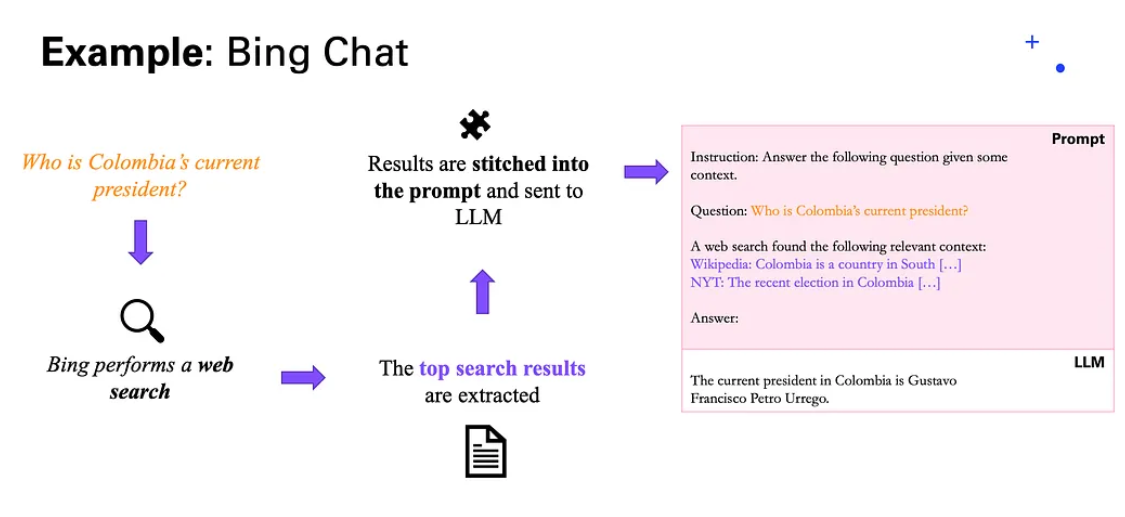
*Bing Chat's implementation of RAG. [image-source: Medium Article](https://medium.com/data-science-at-microsoft/how-large-language-models-work-91c362f5b78f)*
While there are many tools to be able to effectively carry out RAG, for the purpose of this article, we shall understand the concept with the help of the popular open source RAG library [`LLamaIndex`](https://www.llamaindex.ai/)
### LlamaIndex
LlamaIndex is a handy framework that bridges the gap between domain specific custom data and LLMs like GPT, Mistral, Llama etc. The framework offers necessary tooling to access information from a variety of sources, such as, API's, databases, PDFs etc. LlamaIndex democratizes brining data into conversation and context of these smart LLMs paving a way of creating powerfull applications and workflows.
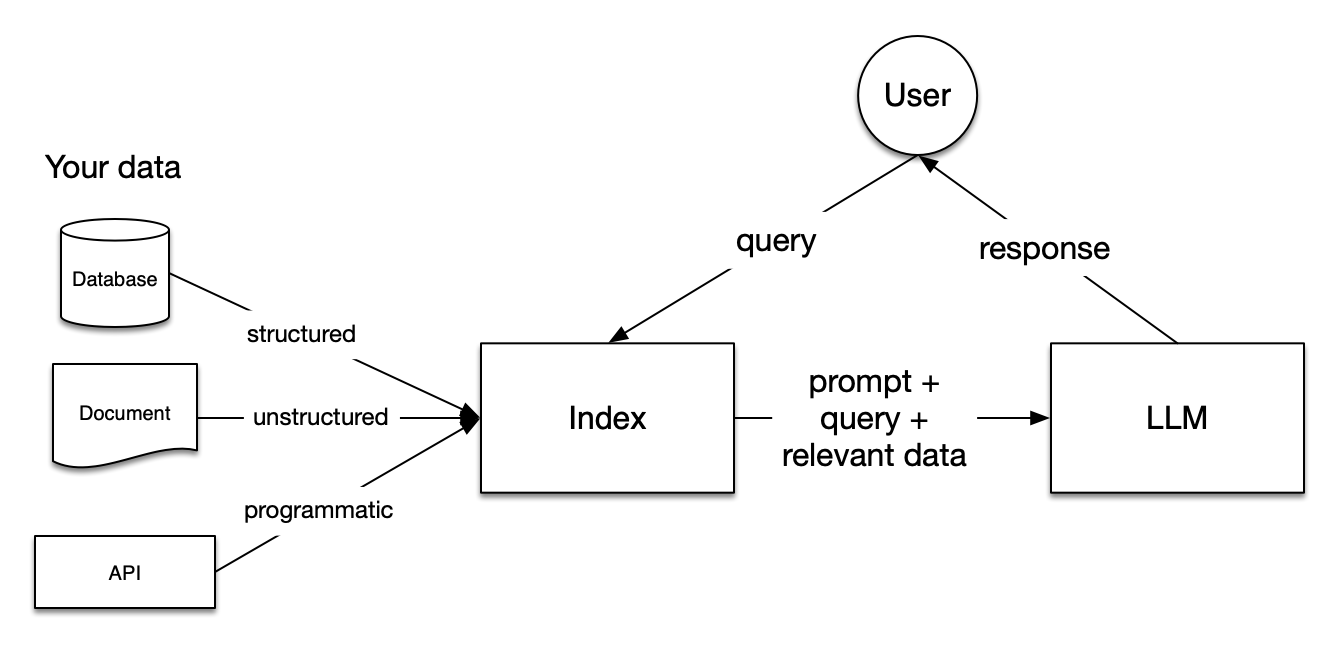
*Basic RAG [image-source: LlamaIndex](https://docs.llamaindex.ai/en/stable/getting_started/concepts.html)*
### Stages of RAG
A typical workflow of RAG has been broken down into the following stages:

*Stages [image-source: LlamaIndex](https://docs.llamaindex.ai/en/stable/getting_started/concepts.html)*
1. **Loading**: This stage involves fetching data from various sources and converting it into a format recognizable by the LLM. Tools like [LlamaHub AI](https://llamahub.ai/) provide multiple connectors for this purpose, or you can build custom connectors using Python.
2. **Indexing**: Here, data is numerically represented to provide the LLM with the right context for effective querying. Metadata plays a critical role in refining this process.
3. **Storage**: This involves storing the indexed data in persistent memory to avoid re-indexing.
4. **Querying**: At this stage, the indexed data is queried to provide the necessary context.
5. **Evaluation**: This is an objective assessment of the accuracy, relevance, and speed of the LLM's responses.
#### Glossary
- **Loading Stage**:
- *Documents*: Containers for data sources (e.g., PDFs, API outputs, database data).
- *Nodes*: Atomic data units in the Llama index, representing portions of the source document.
- **Indexing Stage**:
- *Indexes*: Created by generating vector embeddings of nodes and storing them in a vector store.
- *Embeddings*: Numerical representations of data, essential for delivering accurate context.
- **Querying Stage**:
- *Retrievers*: Define how to efficiently retrieve context from the index.
- *Routers*: Determine which retriever to use for a given query.
- *Node Post Processors*: Apply transformations, filtering, and re-ranking to retrieved nodes.
- *Response Synthesizer*: Generates LLM responses based on user queries.
Lets put all the theory and context into action.
### Quick Demo:
Lets build a query engine with responses to the query synthesized with the help of LLMS. This has multiple applications in the areas and for business which have huge repository of documentation and want to enable FAQ service based on the documentation than having to address a limited set of FAQ.
For the purpose of demostration, lets implement a RAG on top of a 1200 page psychiarty textbook allowing students to query textbook in pursuit of specific information
Lets begin by importing necessary packages
```python
import os
import logging
import sys
from llama_index import ServiceContext, StorageContext
from llama_index.llms import OpenAI
from llama_index import SimpleDirectoryReader
from llama_index import VectorStoreIndex, load_index_from_storage
```
Necessary configurations and setting the defaults.
```python
# Environment setup and logging configuration
os.environ["OPENAI_API_KEY"] = "your-api-key"
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
# Initializing the LLM with OpenAI GPT-4
llm = OpenAI(temperature=0.1, model="gpt-4")
service_context = ServiceContext.from_defaults(llm=llm)
```
Here we will be leveraing the OpenAI LLM model to be able for response synsthesis and for encoding the documents into a vector store
The next step is to read the documents using a one of the loader classes available for reading documents from a directory and convert them into vectors that can be queried.
It is important to note that that steps are involved between loading the documents to storing them as index has been abstracted by LlamaIndex. LlamaIndex allows customization at various stages - Refer their excellent documentation for more!
```python
# Loading and Indexing Process
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
print("Loading a pre-existing index")
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
```
Let us query the index to and synthesize the respinse. Again, many steps are abstracted and can be customized based on need.
```python
# Querying Process
query_engine = index.as_query_engine()
response = query_engine.query("What is child neglect?")
print(str(response))
# Displaying context information if available
if hasattr(response, 'metadata'):
document_info = str(response.metadata)
context_info = re.findall(r"'page_label': '[^']*', 'file_name': '[^']*'", document_info)
print('
' + '=' * 60 + '
')
print('Context Information')
print(str(context_info))
print('
' + '=' * 60 + '
')
```
Voila, you have just build your first simple RAG. What we have built here is the most simple workflow in harnessing the power of LLMs based on specific domain of information. The possibilities are endless with LLamaIndex, from choosing custom LLMs models (Local & Hosted), to document injestion, chunking, vectorization, storage options, retrival stratgies and so on!
### Conclusion
RAG, combined with LLMs and embedding theory, can effectively mine information from extensive datasets. This capability is invaluable in business intelligence and analytics, enabling sophisticated data interactions, like 'conversing' with a book. In our next article, we'll explore additional aspects across each RAG stage, further delving into its practical applications in our field.
---
Stay tuned for more insights into how these technologies are revolutionizing our approach to data science and analytics.